












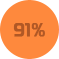


























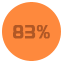




 Консультация
Консультация
 Анализ сайта
Анализ сайта
 Оптимизация
Оптимизация























15
Дек
В Поиске по изображениям Google появились расширенные сниппеты для товаров
Google добавил в мобильную версию поиска по картинкам поддержку разметки для страниц товаров. Расширенные сниппеты можно увидеть по клику на изображение товар... Читать далее

